

U.S AI Training Dataset Market Share, Size, Trends, Industry Analysis Report, By Type (Audio, Image/Video, Text); By Vertical; Segment Forecast, 2024 - 2032
- Published Date:Apr-2024
- Pages: 115
- Format: PDF
- Report ID: PM4870
- Base Year: 2023
- Historical Data: 2019-2022
Report Outlook
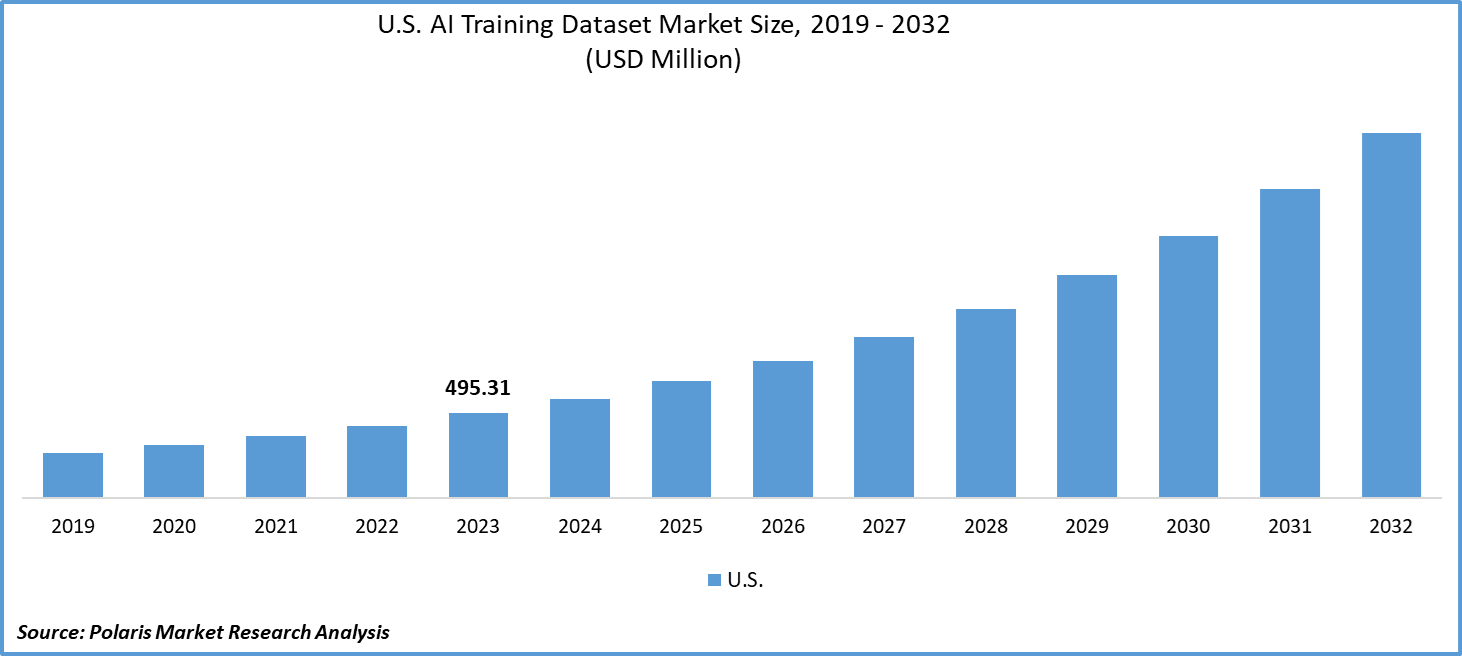
The U.S. AI Training Dataset Market was valued at USD 495.31 million in 2023. It is anticipated to grow from USD 580.50 million in 2024 to USD 2,137.26 million by 2032, exhibiting a CAGR of 17.7% during the forecast period.
U.S AI Training Dataset Market Overview
The artificial intelligence allows the machines to learn from their mistakes and can imitate humans also. They can change according to the situation, through collecting data and studying it in order to discover patterns for given work that can be done. High qualitative datasets are prerequisites for the training of the machines to carry out the tasks assigned with great accuracy and their efficiency depending majorly on data quality. Considering this U.S. training dataset market trends, the delivery of high-grade learning samples is crucial not only for enabling data preparations to be efficient but also for enhancing prediction accuracy. However, U.S. AI training dataset market players, by and large, have started signing deals that can strengthen data quality and understanding of the critical relevance of data in improving AI fitness levels.
To Understand More About this Research:Request a Free Sample Report
In terms of technical advancements, the specific features in the AI field of natural language processing and image generation AI stand out, giving the leaders in the industry the ability to create unforeseen opportunities and make their advantage firm. As the call centers grow through the enhancement of customer experience and the fashion of chatbots, the NLP demand and large language models (LLMs) are hitting the nail on the head. It is ChatGPT, which comes under the category of machine learning models and can be known as LLMs, i.e.. These language learning models have, in fact, changed the character of training datasets that have now become like a human's interaction of dialogue.
Furthermore, AI chatbots gained an exceptional milestone after many models came up that held the same level of mission, applying the diversity and abundance of educational knowledge. The deploying of the software by the main software companies not only as the hardware purchasing from the equipment firms like Amazon Web Services, Microsoft, Google, or IBM but also. Methodically, the commoditization of neuro-tech widgets in this situation will boost the business sector and impart them with so many benefits. Still, other complex systems like image-generating AI models or large language models can be the game changers that can give businesses the leeway to develop and innovate their ways of operation, resulting in improved productivity and growth of companies.
Additionally, Advanced machine learning depends on the quality of the data sets. Thus, companies that are on the crest of the wave are hurried to allocate that consideration towards data cleaning and formatting, model engineering and version management, and work on training, validation, and testing. Unlike the set as a whole American agencies are particularly interested in data variety that also comprises the factors of data richness and purity. One critical standpoint is that the increasing documentation of the large amount volume will increase the demand for quality data on the matter of reliability and consistency of the marked data.
U.S AI Training Dataset Market Dynamics
Market Drivers
Expeditious Expansion of AI and Machine Learning are Bolstering the Growth of the U.S. AI Training Dataset Market Share
Big data is on the verge of taking the development of artificial intelligence to the next level, which requires not only harnessing, storing, and analyzing huge data sets but also certain intelligence. More and more end-users are looking into equipping these computational models with bespoke features that allow AI solutions to cater to Big Data thus making adoption of the AI solutions easy and rapid. The annotated data is a powerful tool in reducing the training time of AI models and machine learning systems working in such essential directions as language recognition or image identification, as well as boosting the demand for AI training sets.
Data annotation construction represents the linchpin of establishing an AI approach for producing clear data required by machines that will then predict the results and thus will provide decisions. On the same note, diverse use of public and private sectors’ reliable sources is also conducted, yielding specific information in different areas like marketing, medical informatics, fraud detection, cyber security, and national intelligence. The individual data point being progressively refined by an ongoing endeavor of annotation enables the data set to be labeled through a systematic approach, thereby increasing the choices offered to an AI training dataset.
Market Restraints
Legal and Ethical Issues are Likely to Hamper the Growth of the Market
According to the US AI training dataset industry, a number of major obstacles, including those in relation to legal and ethical issues surrounding data protection and sensitivity, are there. Since AI algorithms are heavily accurate only by making the essential training a fundamental logical step, sensitive or private information within the results of these algorithms raises some legal and ethical problems. Businesses handling the data space should often get ready to go past the legal requirements and business ethics that govern how data is collected, applied, and protected. Nevertheless, while coping with the intricacies of regulation can be a hard nut to crack, it can, in the extreme, impede access to an appropriate amount of training samples. Data privacy is also an issue, such as data that requires organizations to gather data and implement ethical concerns. Therefore, other organizations may use or share a dataset to achieve its breadth or diversity.
However, the exacting laws and morals on which datasets for AI training are being collected and used may result in stricter monitoring of regulators as well as advocacy groups. The need to adhere to laws about data protection, such as the General Data Protection Regulation (GDPR) and ethical principles that professional associations and industry bodies have laid down, is demanded to prevent legal problems and ensure that the user's private information is protected. On the other hand, the success of such regulations will largely depend on the availability of compliance resources that often may not be financially or technically possible for smaller organizations or startups with little funding and technical expertise. Thereby, the applicable regulation may drive away the businesses that want to immerse in the AI training dataset market, which makes the shortage of comfortable datasets even more difficult.

Report Segmentation
The market is primarily segmented based on type and vertical.
|
By Type |
By Vertical |
|
|
To Understand the Scope of this Report:Speak to Analyst
U.S AI Training Dataset Market Segmental Analysis
By Type Analysis
- In 2023, the image/video segment dominates the U.S. AI training dataset market revenue share. This growth trajectory is attributed to the increasing adoption of applications and the introduction of novel datasets. Key industry players like IBM, Google, and Microsoft have expanded their offerings to bolster their presence in various regions. For instance, in October 2022, Google showcased its development of an AI system called Imagen Video, capable of generating video clips from text inputs.
- The audio segment is positioned for significant expansion driven by increasing demand for AI training in language translation, natural language processing, and speech recognition. Notably, audio datasets play a crucial role in the advancement of AI models capable of processing and comprehending audio inputs. The rising popularity of voice-controlled devices and virtual assistants underscores the necessity for AI training datasets to deliver smoother experiences and more accurate responses.
By Vertical Analysis
- During the projected period, the automotive segment emerged as the top revenue generator and is expected to experience substantial growth, particularly with the increasing prevalence of autonomous vehicles. Stakeholders are placing significant emphasis on producing high-quality, human-labeled, error-free, and cost-effective AI training data tailored for autonomous vehicles. Additionally, there is a notable surge in demand for machine learning algorithms alongside the rise in labeled training datasets.
- The IT segment is expected to make a significant contribution to the U.S. AI training dataset market size growth, driven in part by the adoption of machine learning (ML) models. This involves the gathering and labeling of training data encompassing various forms such as audio, video, images, text, sensor data, and 3D point clouds. IT firms are increasingly leveraging advanced tools to enhance annotation quality, speed, and accuracy, thereby facilitating the training and development of AI algorithms.
Competitive Landscape
The U.S. AI training dataset market is characterized by a diverse array of players ranging from established tech giants to specialized startups. These companies compete to offer high-quality, diverse datasets covering various domains. Additionally, with the increasing demand for AI training datasets across industries, including healthcare, automotive, and retail, competition is intensifying as companies strive to differentiate themselves through innovative data annotation techniques, superior data quality, and robust platform capabilities.
Some of the major players operating in the U.S market include:
- Alegion
- Amazon Web Services, Inc.
- Appen Limited
- Cogito Tech LLC
- Deep Vision Data.
- Google, LLC (Kaggle)
- Lionbridge Technologies, Inc.
- Microsoft Corporation
- Samasource Inc.
- Scale AI Inc.
Recent Developments
- In February 2024, Google entered into an agreement valued at USD 60 million annually with Reddit, granting Google immediate access to Reddit's data. In exchange, Google will utilize its AI technology to improve Reddit's search functionalities.
- In February 2024, Microsoft revealed a significant investment of approximately USD 2.1 billion in Mistral AI to accelerate the expansion and implementation of large language models. The U.S.-based tech giant is anticipated to support Mistral AI with Azure AI supercomputing infrastructure, ensuring superior scalability and performance for AI training and inference tasks.
- In September 2023, SCALE AI unveiled an injection of over USD 20 million into five AI projects aimed at assisting companies of various sizes in enhancing their efficiency and productivity.
Report Coverage
The U.S. AI Training Dataset market report emphasizes key regions across the globe to help users better understand the product. The report also provides market insights into recent developments and trends and analyzes the technologies that are gaining traction around the globe. Furthermore, the report covers an in-depth qualitative analysis of various paradigm shifts associated with the transformation of these solutions.
The report provides a detailed analysis of the market while focusing on various key aspects, such as competitive type, vertical, and futuristic growth opportunities.
U.S AI Training Dataset Market Report Scope
|
Report Attributes |
Details |
|
Market size value in 2024 |
USD 580.50 million |
|
Revenue Forecast in 2032 |
USD 2,137.26 million |
|
CAGR |
17.7% from 2024 – 2032 |
|
Base year |
2023 |
|
Historical data |
2019 – 2022 |
|
Forecast period |
2024 – 2032 |
|
Quantitative units |
Revenue in USD million and CAGR from 2024 to 2032 |
|
Segments Covered |
By Type By Vertical |
|
Customization |
Report customization as per your requirements with respect to countries, regions, and segmentation. |
FAQ's
U.S AI Training Dataset Market report covering key segments are type and vertical.
U.S. AI Training Dataset Market Size Worth $ 21,137.26 Million By 2032
The U.S. AI Training Dataset Market exhibiting a CAGR of 17.7% during the forecast period.
The key driving factors in U.S AI Training Dataset Market
© 2025 Polaris Market Research and Consulting. All rights reserved