

AI Training Dataset Market Share, Size, Trends, Industry Analysis Report, By Type (Audio, Text, Image/Video); By End-Use; By Region; Segment Forecast, 2024 - 2032
- Published Date:Jan-2024
- Pages: 116
- Format: PDF
- Report ID: PM3309
- Base Year: 2023
- Historical Data: 2019-2022
Report Outlook
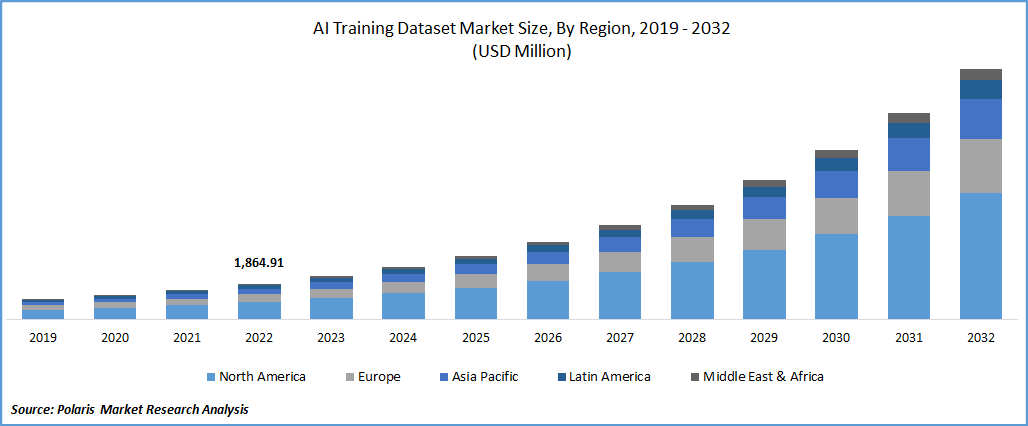
The global AI training dataset market size and share was valued at USD 2260.27 million in 2023 and is expected to grow at a CAGR of 21.5% during the forecast period. The market's growth is attributed to the growing demand for application-specific training data-driven applications such as voice and image recognition. With the increase in demand for AI training datasets, various data providers focus on providing better quality and richer data sets for their customers. The increasing popularity of artificial intelligence (AI) has also led to an increase in demand for training datasets, which allows developers to build more accurate models through more sophisticated algorithms.
AI training data is the synchronization of stamped instances utilized to train machine learning models. The data can acquire several configurations, such as image, audio, text, or ordered data, and each instance is linked with the output stamp or notation that recounts what the data constitutes or how it should be categorized. Training data is utilized to instruct machine learning algorithms to identify motifs and forecast. By catering to extensive amounts of data with recognized labels, a machine learning algorithm can assimilate to identify motifs and forecast contemporary, unobserved data.
The quality and aggregate of training datasets are crucial to the preciseness and productivity of machine learning models. The AI training dataset market sales are soaring as the more varied and illustrative the data is, the greater the model can discern and execute on contemporary, unobserved data. On the contrary, distorted or imperfect training data can cause unsound or unjust forecasts.
To Understand More About this Research: Request a Free Sample Report
AI training datasets are essential for developing and deploying machine learning models. These datasets are used to train and test algorithms that enable computers to learn from data and make predictions or decisions based on that knowledge. The quality and diversity of training data significantly impact the performance of AI models. The quality of training data can significantly impact the accuracy, reliability, and bias of the resulting AI model.
They provide the data to train algorithms to recognize patterns and make predictions. However, creating high-quality training data is a significant challenge that requires substantial resources, expertise, and attention to detail. To develop effective and unbiased AI models, it is crucial to create training datasets that are diverse, representative, and sufficiently large to provide enough data for machine learning algorithms to learn.
The advancements in data collection technology have led to a vast amount of data being generated daily. This data is collected through various sources such as social media, sensors, and IoT devices. Companies collect and analyze data to gain insights into consumer behavior, industry trends, and market opportunities. This need for data-driven decision-making is driving the growth of AI datasets. AI models are trained on this data to provide insights and predictions critical for businesses to remain competitive.
The AI training dataset market report details key market dynamics to help industry players align their business strategies with current and future trends. It examines technological advances and breakthroughs in the industry and their impact on the market presence. Furthermore, a detailed regional analysis of the industry at the local, national, and global levels has been provided.

Industry Dynamics
Growth Drivers
AI datasets are growing rapidly due to various factors, including advancements in data collection technology, the need for data-driven decision-making, the growth of AI applications, open data initiatives, and the development of cloud computing. Open data initiatives have made vast amounts of data accessible to researchers, businesses, and the general public. These initiatives are driving the growth of AI datasets by providing researchers and companies with access to high-quality data that can be used to train AI models.
Cloud computing has made storing and processing large amounts of data easier and cheaper. The growth of cloud computing has made it easier for businesses and researchers to store and process the massive payments of data required to train AI models. This has led to the growth of AI datasets. Both technological advancements and societal changes drive the development of these datasets. AI datasets are expected to grow as the demand for AI applications grows. Businesses and researchers need access to high-quality data to train AI models that can make accurate predictions and provide valuable insights.
Factors such as the increasing demand for AI training datasets and investment in AI technology are driving their growth in this market. The dynamic nature of AI training datasets allows businesses to add new data with minimal effort, resulting in faster development times and lower costs. The AI training dataset market is driven by the demand for better quality data and enhanced accuracy of results. Advancements in technology, as well as new application domains, are helping to shape the AI training dataset market over time. Companies have also invested in emerging areas such as artificial intelligence and machine learning, which require large volumes of training data. This trend has increased demand for real-world assets, such as images of objects that can be labeled with a single tag or classifier.
The increasing use of AI in different domains, including healthcare and insurance, will increase the demand for training datasets. Companies need to maintain an efficient data cleaning process as well as use advanced machine learning algorithms to predict customer preferences based on the data that's been collected. In addition, AI technology is becoming more prominent among stakeholders (tech leaders, investors, customers), requiring additional training datasets to improve performance.
Report Segmentation
The AI training dataset market is segmented based on type, end-use, and region.
|
By Type |
By End-Use |
By Region |
|
|
|
For Specific Research Requirements: Request for Customized Report
The image/ video segment is expected to witness the fastest growth in the forecast period
The image/ video segment is expected to witness the fastest growth over the study period, owing to the rising focus of key players to launch new datasets with the rising number of applications with an increasing number of applications. In May 2020, Google, a multinational technology company, announced the launch of a new artificial intelligence training dataset named Google-Landmark-v2, containing millions of images of thousands of landmarks. Furthermore, the company issued two challenges: landmark recognition 2020 and landmark retrieval 2020; these datasets were developed for image retrieval, instant recognition, and training more robust and efficient systems.
The text segment garnered the largest revenue share and is expected to dominate its position over the study period. This is primarily due to the high usage of text datasets in the IT sector for various automation processes. This includes speech recognition, text classification, and caption generation. Text datasets are commonly used in natural language processing (NLP) applications such as sentiment analysis, machine translation, and text classification.
IT & Telecom accounted for the largest market share in 2022
In 2022, the IT & Telecom segment accounted largest market share owing to the increasing demand for AI solutions from the banking, insurance, and financial services industries. In this domain, current and future technologies are used to automate decisions in strategic areas such as production planning, inventory management, manufacturing scheduling, etc. The development of cloud computing and the emergence of big data drive the demand for AI training datasets. With the increasing adoption of artificial intelligence-based services, enterprises need more training data sets to accelerate their innovation process. These data sets can be generated internally or using external sources such as open-source software.
The healthcare segment is expected to grow significantly in the forecast period as these datasets are used for training AI models to assist in medical diagnosis and treatment. They include medical images, patient records, and other healthcare data. Examples of healthcare datasets include the MIMIC-III (Medical Information Mart for Intensive Care III) dataset, which contains de-identified patient records from over 40,000 patients in intensive care units, and the ChestX-ray8 dataset, which has over 100,000 labeled chest X-ray images.
North America garnered the largest revenue share in 2022
North America garnered the largest share. Vendors are focusing on releasing new datasets to propel the adoption of artificial intelligence technology in the region. In September 2020, Waymo released a dataset for autonomous vehicles collected from the camera sensors & the LiDAR in the form of pedestrians, signage, cyclists, and others. Adopting such datasets in the market creates the demand for AI-based datasets and their further use in transforming services.
Furthermore, Asia Pacific is anticipated to expand rapidly in the forecast period. The growth in the region is attributed to the adoption rate of emerging technologies and the expansion of various market players in the area. Companies in developing nations such as India are adopting innovative technologies at a higher rate. The number of multiple players concentrates on their expansion in the Asia Pacific region. For instance, Microsoft created the indoor location dataset to collect various data from buildings in cities in China, with geomagnetic fields and indoor wi-fi signatures.
Competitive Insight
Some of the major players operating in the global market include Cogito Tech, Amazon Web services, Sama Inc., Alegion, Google, Microsoft Corporation; and Deep Vision Data.
Recent Developments
- In March 2021, OpenAI, one of the leading AI research companies, developed several large-scale pre-trained models, such as GPT-2 and GPT- 3, which have been trained on massive datasets. They have also released several open-source datasets, which have been used to introduce a wide range of natural language processing (NLP) models.
- In September 2020, Google released a unique dataset for autonomous vehicles. Google has developed several datasets for training AI models, including the Google Open Images dataset, which contains millions of images labeled with object tags.
- In July 2020, Microsoft released several datasets for training AI models, including the Microsoft dataset, which contains millions of images with object tags, and the MS MARCO dataset, which includes search queries and their corresponding human-generated answers.
- In June 2021, Amazon developed several datasets for training AI models, including the Amazon Web Services (AWS) Public Datasets, which contains datasets from a wide range of industries, and Amazon Berkeley Objects, which enable new efficient AI models for image-based shopping.
AI Training Dataset Market Report Scope
|
Report Attributes |
Details |
|
Market size value in 2024 |
USD 2,740.58 million |
|
Revenue Forecast in 2032 |
USD 12,993.78 million |
|
CAGR |
21.5% from 2024 – 2032 |
|
Base year |
2023 |
|
Historical data |
2019– 2022 |
|
Forecast period |
2024 – 2032 |
|
Quantitative units |
Revenue in USD million and CAGR from 2024 to 2032 |
|
Segments Covered |
By Type, By End-Use, By Region |
|
Regional scope |
North America, Latin America, Europe, Middle East & Africa, Asia Pacific |
|
Key Companies |
Cogito Tech LLC; Amazon Web Services, Inc.; Sama Inc.; Alegion; Google, LLC; Microsoft Corporation; Deep Vision Data; Appen Limited. |
Explore the landscape of the AI training dataset in 2024 through detailed market share, size, and revenue growth rate statistics meticulously organized by Polaris Market Research Industry Reports. This expansive analysis goes beyond the present, offering a forward-looking market forecast till 2032, coupled with a perceptive historical overview. Immerse yourself in the depth of this industry analysis by acquiring a complimentary PDF download of the sample report.
Browse Our Top Selling Reports
Automotive Wrap Films Market Size, Share 2024 Research Report
Veterinary Active Pharmaceutical Ingredients Manufacturing Market Size, Share 2024 Research Report
Interposer and Fan-out Wafer Level Packaging Market Size, Share 2024 Research Report
Electronic Filtration Market Size, Share 2024 Research Report
Silicone In Electric Vehicles Market Size, Share 2024 Research Report
FAQ's
The AI training dataset market report covering key segments are type, end-use, and region.
AI Training Dataset Market Size Worth 12,993.78 Million By 2032.
The global AI training dataset market expected to grow at a CAGR of 21.4% during the forecast period.
North America is leading the global market.
key driving factors in AI training dataset market are growing applications of training dataset across diversified industry verticals.
© 2025 Polaris Market Research and Consulting. All rights reserved